
From Exhaustion to Expansion: How We Solved a Fortune 200 Company's IP Crisis
Situation
You have a large organization that's utilizing a ton of IP space inefficiently. Let's face it, nobody's perfect when it comes to planning and predicting the use of proper CIDR blocks. In a world where data centers are considered old school and everything is moving to the cloud, how do you solve this problem? How do you avoid running out of routable IP space? Even more so, how do you leverage your space perfectly while maintaining credibility in an environment where the size of workloads and the levels of on-premise clusters transitioning to the cloud are only increasing? How can you run 10,000 Fargate containers at once while maintaining enough IP space?
Better yet, how can you create a service mesh network that can enable other teams to do a Centralized Fabric approach? All of these questions we at Protagona recently asked ourselves at an Enterprise level, to help enable and accelerate a large organization's move to the cloud. And it turns out, the solution isn't completely straightforward and required a lot of planning, architecture, and shared services.
Task
To move the organization and enable many different teams - from billing to planning - to move to AWS, we had to create a solution that would support and deploy very easily to help teams adopt this new process. If you have been in the field for a while, you will see that while the planning, architecture, coding, and approvals are difficult, the hardest part is adoption. Knowing this, we decided to make a fully automated approach to this new style of cloud networking.
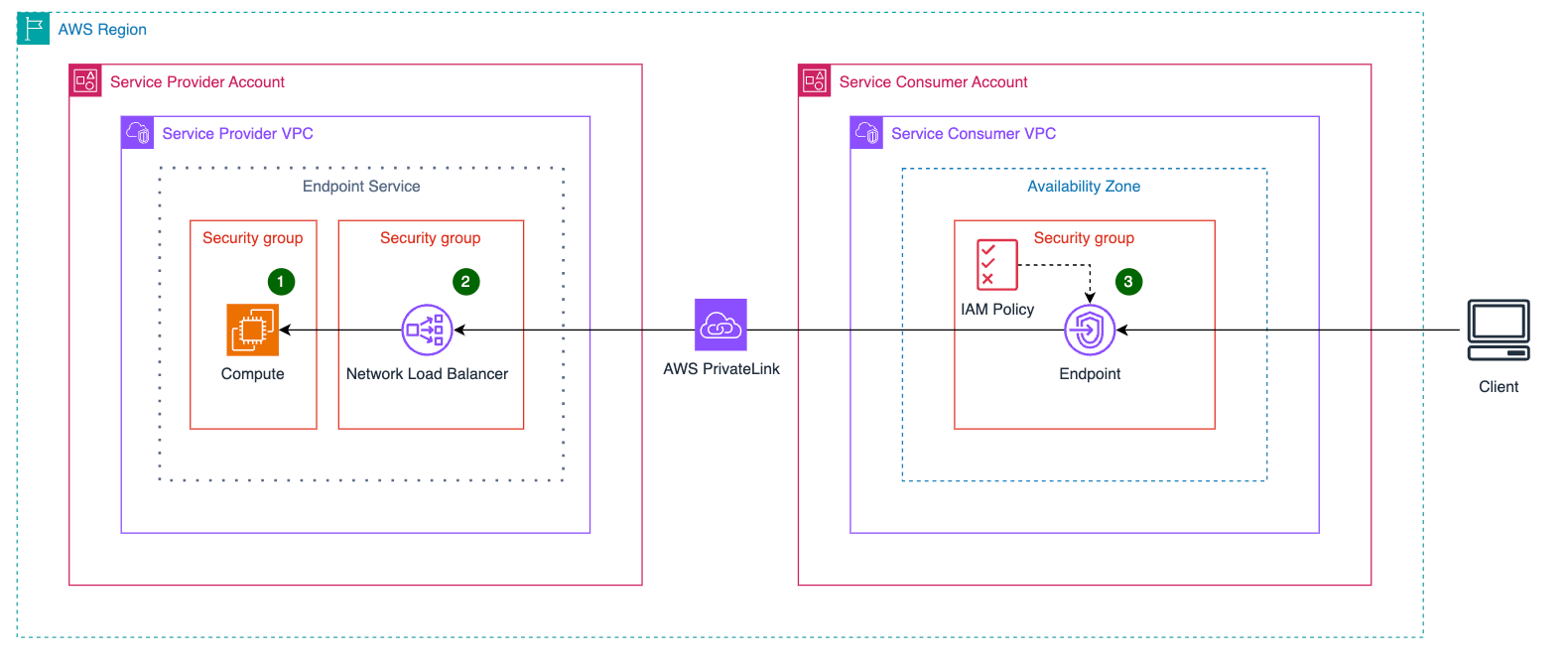
So here's what we developed: AWS PrivateLink Endpoint Services as a pattern to expose internal workloads, or PLES for short. Diving in, the pattern that we must create to solve this looming IP consumption issue is essentially twofold:
- First is the Service Provider, or the creator of the connection. This service provider will have to create an NLB in their VPC and initiate the PrivateLink endpoint services.
- Second is the Service Consumer, and in this case the "Fabric VPC". This shared services fabric VPC is a way that all the teams can connect to each other in a centralized manner.
Action
Here's what we developed for this solution: a multi-step function CloudFormation custom resource Lambda-triggered approach. Initially, we went with an event-based approach leveraging both EventBridge and an API Gateway upon deletion, but it turned out that was more complex to manage and promote adoption.
After learning from this experience, we instead chose to pivot and leverage a CloudFormation custom resource Lambda that, upon creation, would:
- Look up information in the account for things like the PrivateLink endpoint VPC name and NLB details
- Kick off a step function in the fabric account
- Perform a series of lookups and validations on VPC ownership
- Create the PrivateLink endpoint service endpoints in the VPC
Leveraging this architecture style, we were able to automate the process so that when a team creates a PrivateLink endpoint in their account with the right tags, it automatically:
- Kicks off the creation of the corresponding PrivateLink in the fabric account
- Similarly handles deletion by removing it from the fabric account when requested
Down the road, the same method can be used to directly connect services together without even using a fabric VPC, if desired.
Result
With the PLES automation, teams are now able to create routable CIDR blocks as large as the RFC allocations allow. The solution makes it possible to avoid using IPv6 when many apps aren't compatible, while allowing you to virtually use as many IP addresses as you would like. This is achieved by only needing to reserve a very small routable subnet, while the rest are technically private but become routable via PLES.
Key Learnings
Adoption is Everything
The most important lesson learned is that adoption is paramount. Sometimes the best solution isn't the most technically "perfect" one, but rather the solution that teams will actually use. While in an ideal world, we might use Terraform exclusively without custom resources to trigger Lambda functions, the reality is that many organizations don't use Terraform at all. You need to meet organizations where they are and use the cloud-native tools they're most familiar with to get the job done, even if it means more steps.
Access Control Strategy
While ABAC (Attribute-Based Access Control) initially seemed like a natural fit for our PLES implementation, several critical operational and governance requirements led us to implement a more controlled approach:
Backup and Restore Operations
The backup and restore process was a major factor in our decision. Our centralized approach allows us to:
- Maintain consistent backup schedules
- Implement unified retention policies
- Coordinate cross-account restores
- Ensure proper sequencing during disaster recovery
- Track dependencies between endpoints during restore operations
Uniformity and Control Requirements
Standardization was crucial for operational efficiency:
- All endpoints follow the same naming conventions
- Security groups are configured consistently
- Routing policies remain uniform
- Monitoring and alerting maintain the same baselines
- Documentation stays synchronized with actual implementations
Approval Workflow Benefits
The approval process needed to be more nuanced than simple tag-based permissions:
- Teams need to demonstrate compliance with network policies
- Resource quotas must be checked before endpoint creation
- Security teams need visibility into new connections
- Cost allocations need to be verified
- Cross-team dependencies must be documented
Technical Limitations and Considerations
While VPC Lattice is a newer AWS service for service networking, it currently lacks UDP and TCP routing support. AWS PrivateLink, being a mature and battle-tested service, provides the stability and feature set we need for production traffic.
Our decision to use PrivateLink over VPC Lattice was driven by:
- PrivateLink's proven track record in production environments
- Complete feature set for our networking requirements
- Mature tooling and documentation
- Extensive operational experience across the industry
Though VPC Lattice offers some interesting capabilities, both its cost structure and current limitations made it unsuitable for our immediate needs.
Bonus Resources
I've open-sourced my SIGV4 tokenization self-signing automation script that was initially built for the event-based architecture approach (though we didn't end up using it). Feel free to check out my GitHub repo if you want to use it for your own projects!